Teil 1: Die Logik künstlicher Intelligenz
Dec. 24, 2025
KI, Expertensystem, GPS
Heutzutage ist es schwierig, das Thema KI zu ignorieren. Es kommt aus allen Ecken. Die einen sagen einen Zusammenbruch der Wirtschaft voraus und warnen vor Gefahren, die anderen singen ein Loblied auf die KI und verheißen eine unbeschwerte Zukunft, in der der Mensch sich einem Kunst widmet, während die Maschinen für uns arbeiten. In jedem Fall ist es klar: KI ist bereits hier bei uns - und wird bleiben. Deshalb müssen wir gut verstehen, worüber wir sprechen. Das ist eine kurze Einführung zum großen Gebiet.
Was nennt man "künstliche Intelligenz"?
Die Geschichte des Begriffs künstliche Intelligenz beginnt 1956. Prominente Wissenschaftler und Forscher versammelten sich damals, darunter John McCarthy, Claude Shannon, Marvin Minsky, Nathaniel Rochester und andere, im Rahmen des Dartmouth Summer Research Project on Artificial Intelligence am Dartmouth College in Hanover, New Hampshire.
 Hintere Reihe: Oliver Selfridge, Nathaniel Rochester, Marvin Minsky, John McCarthy. Vordere Reihe: Ray Solomonoff (links), Claude Shannon (recht). Quelle.
Hintere Reihe: Oliver Selfridge, Nathaniel Rochester, Marvin Minsky, John McCarthy. Vordere Reihe: Ray Solomonoff (links), Claude Shannon (recht). Quelle.
Trotz der Schwierigkeiten solcher Projekte - wie Finanzierung und Meinungsstreit - hatte dieser Sommer einige sehr wichtige Folgen. Das Gebiet wurde bezeichnet, und seine allgemeinen Ziele wurden formuliert.
Schon damals wurden folgende Aspekte der KI für die Konferenz vorgeschlagen:
- automatische bzw. selbststeuernde Maschinen
- Wie muss ein Computer programmiert werden, um eine Sprache zu benutzen
- Neuronale Netzwerke
- Theoretische Überlegungen zum Umfang einer Rechenoperation
- Selbstverbesserung
- Abstraktionen
- Zufälligkeit und Kreativität.
Außerdem auf der Konferenz die Auffassung vertreten, dass KI ein multidisziplinäres Gebiet sei. Und dort prägte John McCarthy den Begriff "Artificial Intelligence". McCarthy selbst definierte KI so:
"Es ist die Wissenschaft und das Engineering der Erzeugung intelligenter Maschinen, insbesondere intelligenter Computerprogramme. (...) Das Problem besteht darin, dass wir im Allgemeinen noch nicht bestimmen können, welche Rechenverfahren wir als intelligent bezeichnen möchten. Einige Mechanismen der Intelligenz verstehen wir, andere nicht. (...) Daher wird unter Intelligenz vor allem die rechnerische Fähigkeit verstanden, Ziele in der Welt zu erreichen."[1]
Die Forscher stimmen darin überein, dass es schwierig ist, die Intelligenz eindeutig zu definieren. Melanie Mitchell schlägt in ihrem Buch Artificial Intelligence: A Guide for Thinking Humans vor, die Definition von Intelligenz im allgemeinen Sinn zu ignorieren und stattdessen KI aus zwei Perspektiven zu betrachten: - Wissenschaftlich: der Versuch, die Mechanismen der natürlichen (biologischen) Intelligenz in Computern einzubetten. - Praktisch: die Entwicklung von Computerprogrammen, die Aufgaben so gut oder besser als Menschen lösen.
Stuart Russel und Peter Norvig formulieren die Frage "Was ist KI?" in ihrem Artificial Intelligence: A Modern Approach zur Frage "Was ist Intelligenz?" um - basierend auf der Annahme, dass der Begriff künstliche gut verstanden ist - und identifizieren Intelligenz mit Rationalität. Konkret definieren sie das Gebiet als die Entwicklung intelligenter Agenten: Funktionen, die die Informationen aus der Umgebung aufnehmen und entsprechendes Verhalten erzeugen.[2]
Es gibt noch Tausende weiterer Meinungen und Definitionen. Allgemein kann man jedoch sagen:
KI ist ein computergestütztes System - oder ein Verbund solcher Systeme -, das Informationen aus der Umgebung analysiert, Entscheidungen trifft, um Ziele zu erreichen. Gleichzeitig ist KI auch der Teilbereich der Informatik, der solche Systeme erforscht und entwickelt.
Die Dartmouth-Konferenz markierte den Anfang der Begeisterung in der Industrie und einen starken Optimismus. In den folgenden Jahren wurden erste wichtige Forschungsinstitutionen gegründet, wie Stanford Artificial Intelligence Laboratory und MIT AI Lab. Erste große Investitionen begannen.
Der Erfolg der ersten symbolischen Programme für Logik und Spiele (z. B. Schach) war spektakulär. KI-Forscher wie Herbert Simon, Allen Newell und Marvin Minsky glaubten, man könne menschliche Intelligenz in weniger Jahre nachbilden. Dies war der erste AI Summer.
Doch auf jeden Sommer folgt ein Winter. In der Mitte der 1970er trafen die Entwickler und Forscher, vor dem Hintergrund hocher Erwartungen, auf erhebliche Hindernisse: die Einschränkungen der Rechenleistung, die begrenzte Datenmengen sowie die Unvollkommenheit der damaligen Ansätzen und Algorithmen. Die Finanzierung nahm ab, und der AI Winter begann. Das wissenschaftliche Interesse jedoch stieg weiter.
Von symbolischer KI zu statistischen Ansätze
In den ersten drei Jahrzehnten der KI-Forschung dominierte ein grundlegender Ansatz, der heute als klassische symbolische KI bezeichnet wird. Die Pioniere der KI betrachteten menschliche Intelligenz durch das Prisma der traditionellen westlichen Philosophie, die bei Aristoteles ihren Ursprung hat und sich in Descartes' Trennung von Denken und Körper fortsetzt. Logik, Mathematik und Problemlösungsfähigkeit galten als zentrale Eigenschaften des menschlichen Geistes und als das, was den Menschen vom Tier unterschiedet. Entsprechend wurde Logik als Fundament von Intelligenz verstanden.
Diese Ideen bildeten die Grundlage für Methoden, die unter dem Sammelbegriff symbolische (oder logikbasierte) künstliche Intelligenz bekannt wurden.
Das symbolische KI-Paradigma basiert auf hochgradig abstrakten symbolischen Repräsentationen und klar definierten Regeln der Informationsverarbeitung. Solche Systeme verwenden Wissensbasen, die in menschenlesbaren Symbolen (Wörtern oder Phrasen) kodiert sind, und manipulieren diese mithilfe formaler logischer Regeln.
General Problem Solver
Zu den ersten Programmen, die große Aufmerksamkeit erregten, gehörten der Logic Theorist und der General Problem Solver (GPS) von Herbert. A Simon und Allen Newell.
Der General Problem Solver wurde 1957 entwickelt und beruhte auf der Idee, dass das ein Computerprogramm jedes Problem lösen könne, sofern dieses in geeigneter Form beschreiben wird. Der GPS war so beeindruckend, dass einige KI-Forscher glaubten, eine große Ära intelligenter Maschinen habe begonnen. Simon behauptete sogar, es gebe bereits Maschinen, die denken, lernen und kreativ handeln, und dass der Umfang der von ihnen lösbaren Probleme bald mit dem menschlichen Intellekt vergleichbar sei.
Diese Hoffnungen erfüllten sich zwar nicht vollständig, dennoch war der GPS in konzeptioneller Hinsicht ein Meilenstein: Zum ersten Mal wurde die Strategie der Problemlösung vom spezifischen Problemwissen getrennt.
Wie Peter Norvig in Paradigms of Artificial Intelligence Programming anmerkt, war der GPS in der Programmiersprache IPL implementiert, die selbst eine erhebliche Komplexität mit sich brachte. Ironischerweise könnte gerade diese Komplexität die Ursache für die weitreichenden Erwartungen gewesen sein: Wenn ein Programm so kompliziert ist, so Norvig, muss es etwas Bedeutendes leisten.
Als klassische Demonstrationsaufgabe symbolischer KI gilt das Problem der Missionare und Kannibalen. Drei Missionare und drei Kannibalen müssen einen Fluss mit einem Boot überqueren. Das Boot kann jedoch nur zwei Personen transportieren und nicht leer fahren. Befinden sich an einem Ufer mehr Kannibalen als Missionare, werden die Missionare gefressen. Wie können alle sicher ans andere Ufer gelangen?
Die symbolische Darstellung, die man in ein Programm wie GPS einführen kann, ist der Anfangszustand:
LINKES_UFER = (3, 3, 1)
RECHTES_UFER = (0, 0, 0)
Dabei bezeichnen die Zahlen die Anzahl der Missionare, der Kannibalen und das Boot. Der Zielzustand ist entsprechend:
LINKES_UFER = (0, 0, 0)
RECHTES_UFER = (3, 3, 1)
Die Lösung wird mithilfe von Operatoren erreicht. Für unseres Ziel ist ein möglicher Operator:
BEWEGEN(MISSIONARE, KANNIBALEN, VON_UFER, ZU_UFER)
Das Programm überprüft anschließend die kodierten Regeln, etwa dass die Missionare niemals in der Unterzahl sein dürfen. Für den Computer selbst sind die verwendeten Symbole bedeutungslos: Begriffe wie „Missionare“ oder „Kannibalen“ könnten durch beliebige Zeichen ersetzt werden. Ihre Bedeutung ergibt sich ausschließlich aus den formalen Beziehungen zwischen ihnen. Genau darin liegt das „General“ im General Problem Solver.
Das Schach
Spiele wie Schach oder Go spielten in der Geschichte der KI eine zentrale Rolle. Im Westen galt Schach als Gipfel intellektueller Leistung, ähnlich wie Go in China.
Newell und Simon gingen davon aus, dass alle KI-Aufgaben, z.B. Schach, mithilfe von Suche und Heuristik (heuristische Suche) gelöst werden können. Heuristik bezeichnet Methoden und Theorie zur Organisierung der selektiven Suche bei der Lösung schwieriger intellektueller Aufgaben. In der Informatik kommen heuristische Methoden zum Einsatz, um mit geringem Rechenaufwand und kurzer Laufzeit zulässige Lösungen für ein bestimmtes Problem zu finden.[3]
In der klassischen KI ist Suche eine fundamentale Methode, da sie Listen von Symbolen manipuliert. Aufgaben wie das Beweisen von Theoremen, das Lösen von Rätseln, das Spielen oder die Bewegung im Irrgarten lassen sich als Entscheidungsprozesse modellieren. Die möglichen Entscheidungen bilden einen Entscheidungsbaum.
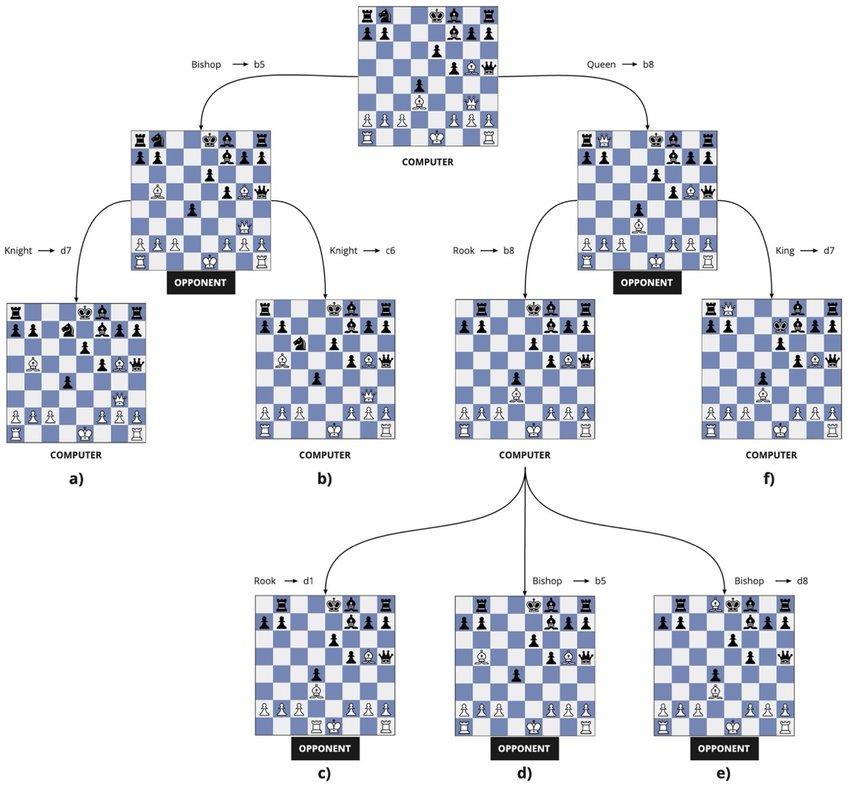 Kleine Teilmenge eines Entscheidungsbaum. Quelle.
Kleine Teilmenge eines Entscheidungsbaum. Quelle.
Claude Shannon entwickelte Anfang der 1950er Jahre ein Modell einer Robotermaus, die einen Ausgang aus einem Irrgarten sucht. An jeder Kreuzung hat sie drei mögliche Wege, was einem Verzweigungsfaktor von drei entspricht. Der einfachste Weg ist, die Varianten nacheinander ausprobieren. Das entspricht einer Brute-Force-Suche. Und auf der jeden Kreuzung geht es so weiter.
Man kann jedoch die Anzahl der Kreuzungen vorgeben, die die Maus überprüfen darf, bevor sie zurückkehrt und einen anderen Weg ausprobiert. Das nennt man Tiefensuche. Wie kann man bemerken, die Menge der Wege, die die Maus überprüfen muss, wächst sehr schnell. Der Verzweigungsfaktor (gleich drei) vervielfacht die Anzahl der Möglichkeiten an jeder Kreuzung jeweils um drei. Die Aufgabe wächst exponentiell und führt zu einer kombinatorischen Explosion.[4]
Im Schach ist dieses Problem noch drastischer: Ein Spieler hat im Durchschnitt etwa 38 mögliche Züge pro Position, somit ist der Verzweigungskoeffizient gleich 38. Eine Partie umfasst im Mittel 42 Züge. Da das Spiel zwei Spieler hat, vervielfacht sich diese Menge um 2, bzw. 3884 - mehr als die Anzahl der Sterne im Universum. Und Schach hat in seinem Entscheidungsbaum etwa 10120 mögliche Partien - mehr als die Anzahl der Atome im Universum (1075). Daraus wurde klar, dass eine Brute-Force-Suche nicht passt, weil sie sehr langsam ist; andernfalls würde die Berechnung ewig dauern.
Um dieses Problem zu bewältigen, fast alle Schachprogrammen verwenden den Minimax-Algorithmus, um einen optimalen Zug zu bestimmen. Newell und Simon schlugen vor, Heuristiken zu benutzen, die Menschen bei der Aufgabenlösung anwenden. Durch Wissen und Erfahrung kann man viele Zweige schnell verwerfen.
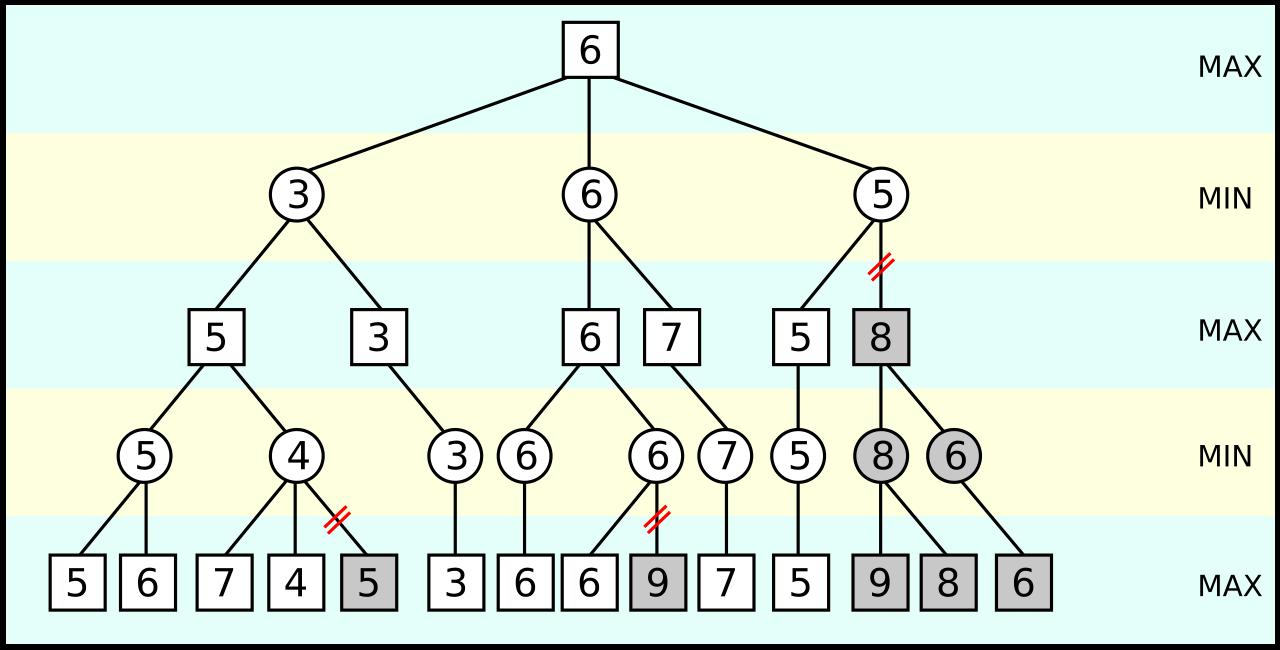 Die graue Zweige wird nicht berechnet. Quelle.
Die graue Zweige wird nicht berechnet. Quelle.
Eine der Heuristiken ist die Alpha-Beta-Suche. Ein Zweig wird nicht weiter berechnet, wenn sein Berechnungsergebnis schlechter ist als ein zuvor berechnendes Ergebnis und weitere Berechnungen die Prognose nur verschlechtern können. Solche Zweige kann der Computer ignorieren. Dieser Ansatz erlaubt es, den Verzweigungsfaktor von 38 bis etwa 6 zu verringern. Außerdem wurde die Tiefsuche damals auf etwa 4 Züge begrenzt, weil die Maschinen sehr schwach waren.
In einer Reihe weiterer Entwicklungen und Verbesserungen der Suchalgorithmen (z.B. die Suche mit iterativer Vertiefung, bei der die Tiefe schrittweise entlang eines Weg erhöht wird, der am vielversprechendes aussieht) entwickelten die Forscher Systeme mithilfe zusätzlichen Wissensbasis über menschliche Ansätze zum Spiel. Dieses Wissen hatte die Form zusätzlicher Heuristiken zur besseren Bewertung von Figurenstellungen sowie von Datenbanken für Eröffnungen und Endspiele. Mit anderen Worten: Man integrierte eine große Menge menschlichen Expertenwissens in die Programme.
Expertensysteme
Andere Systeme, die stark auf Wissensdatenbanken setzten, waren Expertensysteme.
"Die Kraft liegt im Wissen".
- Edward Feigenbaum (Der Vater der Expertensystemen).
Während der Arbeiten in den 1960er Jahren konzentrierten sich viele KI-Forscher auf das automatische Beweisen von Theoremen. Dabei zeigte sich, dass die damaligen Systeme gut mit stark vereinfachten Beispielen funktionierten, jedoch erhebliche Schwierigkeiten mit realistischen, insbesondere NP-schweren Problemen, hatten.
Die in Expertensystemen verfolgten Ansätze stellten eine alternative Richtung dar. Die zentrale Annahme war, dass komplexe Probleme nicht durch allgemeine Problemlösungsstrategien, sondern durch spezialisierte Regeln für konkrete Situationen bewältigt werden können.
Expertensysteme sind ein klassisches Beispiel symbolischer KI und gehörten zu den ersten praktisch eingesetzten KI-Anwendungen. Ihr Ziel ist es, das Entscheidungs- und Schlussfolgerungsverhalten menschlicher Experten in einem eng begrenzten Fachgebiet nachzubilden. Zentrales Merkmal ist die explizite Repräsentation von Wissen in symbolischer Form, meist als Regeln vom Typ Wenn–Dann (IF-ELSE), ergänzt durch Fakten und logische Relationen. Im Gegensatz zu datengetriebenen Verfahren sind die Wissensstrukturen für Menschen nachvollziehbar und überprüfbar.
Der Kern einer Expertensystemarchitektur besteht aus einer Wissensbasis, einem Inferenzmechanismus und einer Arbeitsgedächtniskomponente. Der Inferenzmechanismus wendet die Regeln der Wissensbasis auf konkrete Fakten an und leitet daraus neue Schlussfolgerungen ab, typischerweise mittels Vorwärts- oder Rückwärtsverkettung. Ein wesentliches Merkmal vieler Systeme ist zudem ein Erklärungsmodul, das begründen kann, warum eine bestimmte Entscheidung oder Empfehlung getroffen wurde - ein zentraler Vorteil symbolischer Ansätze.
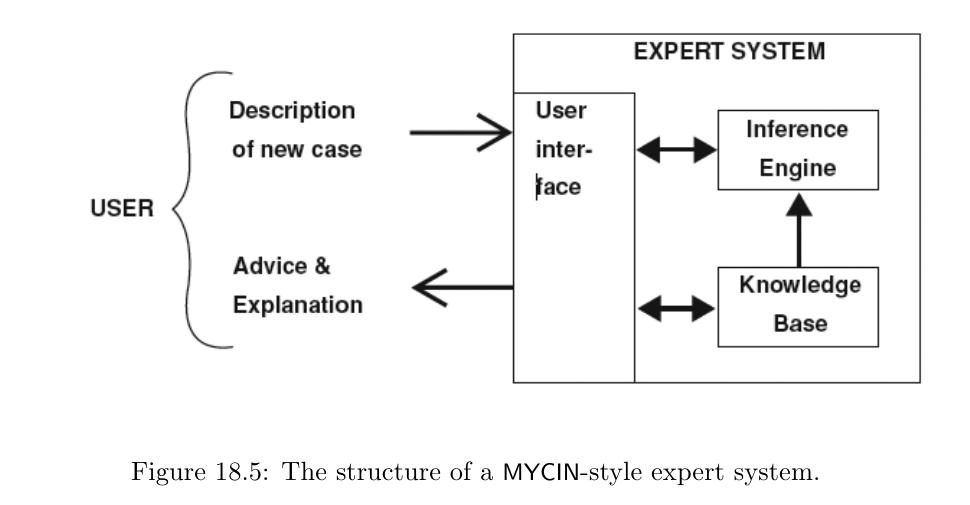 MYCIN (schematische Darstellung). Quelle.
MYCIN (schematische Darstellung). Quelle.
Das bekannteste frühe Expertensystem war MYCIN. Der Name leitet sich von dem Suffix antibakterieller Wirkstoffe ab, etwa Erythromycin oder Clindamycin. Das Projekt wurde 1974 von Edward Shortliffe an der Stanford University entwickelt und diente der Diagnose bakterieller Infektionskrankheiten sowie der Empfehlung geeigneter Antibiotikatherapien. Das Programm wurde in der Programmierschprache LISP geschrieben, die zu dieser Zeit ein zentrales Werkzeug in der KI-Forschung war.
Ein Beispiel einer MYCIN-Regel (nach The Quest for Artificial Intelligence von Nils J. Nilsson, in englischem Pseudocode):
RULE036
PREMISE: ($AND
(SAME CNTXT GRAM GRAMNEG)
(SAME CNTXTM MORPH ROD)
(SAME CNTXT AIR ANAEROBIC))
ACTION: (CONCLUDE CNTXT IDENTITY BACTEROIDES TALLY 0.6)
Die Regel besagt, dass bei bestimmten Eigenschaften eines Erregers (gramnegativ, stäbchenförmig, anaerob) mit einer Wahrscheinlichkeit von 0,6 auf das Bakterium Bacteroides geschlossen wird.
IF:
1) The gram stain of the organism is gramneg, and
2) The morphology of the organism is rod, and
3) The aerobicity of the organism is anaerobic
THEN: There is suggestive evidence (0.6) that the identity
of the organism is bacteroides
Ein entsprechendes Beispiel einer Regel in LISP, die auf den Kontext referiert:
(defrule 36
if (gram is gramneg)
(morph is rod)
(air is anaerobic)
then .6
(identity organism is bacteriodes))
Trotz ihrer Transparenz und Zuverlässigkeit in klar definierten Domänen verloren Expertensysteme ab den 1990er-Jahren an Bedeutung. Hauptgründe waren der hohe Aufwand der Wissensakquisition, geringe Flexibilität und fehlende Lernfähigkeit. Heute erleben ihre Konzepte jedoch eine partielle Renaissance, etwa in hybriden KI-Systemen, in denen regelbasierte Komponenten mit maschinellem Lernen kombiniert werden, insbesondere dort, wo Nachvollziehbarkeit und regulatorische Anforderungen eine zentrale Rolle spielen.
Krise der symbolischen KI
Bis in die 1980er-Jahre dominierten symbolische Ansätze die KI-Forschung. Systeme wie Expertensysteme, wissensbasierte Problemlöser und logische Inferenzmaschinen galten als vielversprechender Weg zu „intelligenten“ Programmen. Mit zunehmender Komplexität der Anwendungsdomänen traten jedoch grundlegende Grenzen dieses Paradigmas immer deutlicher zutage.
Ein zentrales Problem war die Wissensakquisition. Das manuelle Erfassen, Formulieren und Pflegen von Regeln erwies sich als extrem aufwendig und fehleranfällig. Der Prozess, Expertenwissen explizit zu formalisieren, wurde zum sogenannten Knowledge Acquisition Bottleneck. Zudem waren die Systeme stark von der Vollständigkeit und Konsistenz ihrer Wissensbasen abhängig.
Ein weiterer Schwachpunkt war die mangelnde Robustheit gegenüber Unsicherheit und unvollständigen Informationen. Die reale Welt ist geprägt von Rauschen, Mehrdeutigkeiten und statistischen Zusammenhängen, die sich nur schwer in strikte symbolische Regeln fassen lassen. Obwohl Erweiterungen wie Unsicherheitsmaße oder Fuzzy-Logik eingeführt wurden, blieb der Umgang mit probabilistischen Phänomenen begrenzt.
Hinzu kam die fehlende Lernfähigkeit. Klassische symbolische Systeme konnten ihr Wissen nicht eigenständig erweitern oder an neue Situationen anpassen. Jede Änderung der Domäne erforderte manuelle Eingriffe in die Wissensbasis, was die Skalierbarkeit erheblich einschränkte.
Parallel zu diesen Problemen führten wirtschaftliche Enttäuschungen in den 1980er-Jahren zu KI-Wintern, in denen Fördermittel und industrielles Interesse deutlich zurückgingen. Dies verstärkte die Suche nach alternativen Ansätzen.
Der Übergang zum maschinellen Lernen
Bereits ab den 1990er-Jahren verlagerte sich der Fokus zunehmend auf datengetriebene Methoden. Statt Wissen explizit zu modellieren, begann man, statistische Strukturen direkt aus Beispieldaten zu lernen. Diese Entwicklung markiert den Übergang zum maschinellen Lernen (Machine Learning, kurz ML).
Im Gegensatz zur symbolischen KI steht beim Machine Learning nicht die manuelle Wissensrepräsentation im Vordergrund, sondern die automatische Anpassung von Modellparametern auf Basis von Daten. Verfahren wie lineare Modelle, Entscheidungsbäume, neuronale Netze und probabilistische Modelle erwiesen sich als deutlich robuster gegenüber Unsicherheit, Rauschen und unvollständigen Informationen.
Der Durchbruch des maschinellen Lernen wurde zudem durch externe Faktoren begünstigt: die Verfügbarkeit großer Datenmengen, steigende Rechenleistung sowie Fortschritte in der Optimierung und Statistik. Anwendungsbereiche wie Spracherkennung, Bilderkennung und Informationssuche profitierten früh von diesen Methoden und lieferten messbare, reproduzierbare Erfolge.
Der Übergang von symbolischer KI zu ML stellt keinen vollständigen Paradigmenwechsel im Sinne eines Bruchs dar, sondern vielmehr eine Verschiebung der Gewichtung. Während symbolische Methoden an Bedeutung verloren, wurden datengetriebene Ansätze zum dominanten Forschungs- und Anwendungsparadigma (Teil 2). In modernen KI-Systemen werden beide Ansätze zunehmend kombiniert, um sowohl Lernfähigkeit als auch Interpretierbarkeit zu gewährleisten.